

















Estamos Testando o ChatGPT-4.5, o Modelo mais recente, há alguns dias. Veja o que Descobrimos.
Tivemos acesso ao GPT-4.5 nos últimos dias e, Infelizmente, temos o Dever de Informar que ele não é Totalmente Alucinante.
A OpenAI acabou de lançá-lo como uma Prévia de Pesquisa para os Usuários do ChatGPT Pro e, com certeza, ele é muito bom em termos de Benchmark:
- A OpenAI nos disse que obteve 64% no Benchmark Simple QA – quase o Dobro da Pontuação do GPT-4.
O SimpleQA testa o Conhecimento Mundial em Áreas Complicadas sem muitos dados, portanto, ele deve ter Menos Alucinações. Mas essa não é a Grande Manchete.
A OpenAI o classificou como:
- compassivo,
- emocionalmente inteligente,
- e um bom escritor criativo
– mais ou menos como o Claude 3.5, mas melhor – e ele faz jus a isso.
Então, em resumo: Ele pode não surpreender totalmente sua mente, mas, em vez disso, pode fazer amizade com ela.
De Assistente Sem Graça a Melhor Amigo – Depois que Você Se Acostuma
O 4.5 não é um grande avanço em relação ao 4o, mas é um passo em uma nova direção – com menos recusas, respostas mais humanas, respostas mais bem formatadas e menos rigidez.
Antes que
- o sangue sair correndo de seu rosto,
- você começa a se sentir tonto,
- e seus polegares se contorcerem inquietos enquanto começam a compor um tweet em letras maiúsculas sobre O FIM DAS LEIS DE ESCALA,
pare e respire fundo. Vamos aplicar uma compressa fria e um aforismo calmante:
Não entrem em pânico.
Um Aparente Objetivo da OPenAI para o 4.5
Veja a seguir o porquê:
1. Essa mudança é surpreendentemente oportuna. Esta semana, a Anthropic lançou o Claude 3.7 Sonnet com capacidade de codificação significativamente melhorada, mas com muito menos calor e inteligência emocional do que o 3.5. Portanto, há muito espaço aberto para outro modelo que possa ser
- criativo,
- empático,
- criativo, empático e solidário
- e de apoio em sua vida cotidiana.
E esse parece ser o objetivo da OpenAI com o 4.5.
2. É importante reconhecer a realidade. Isso é decepcionante. No início deste ano, o The Information e outros veículos noticiaram rumores de que o “Projeto Orion” da OpenAI não estava tendo o desempenho esperado em termos de inteligência, e esses rumores parecem estar corretos. Presumivelmente, a OpenAI gastou muitos recursos no GPT 4.5 e, em um mundo em que as coisas estivessem ocorrendo conforme o planejado, isso nos deixaria impressionados – especialmente porque o Claude 3.7 Sonnet está sendo elogiado por sua capacidade de codificação.
3. Vamos ter alguma perspectiva. Às vezes, leva-se algum tempo para conhecer um modelo. Estamos entrando em um território em que a interação com modelos por meio de bate-papo não é suficiente para entender seus recursos. Precisamos usá-los em outros aplicativos – como Cursor, Cora, ou Sparkle – e criar novos benchmarks (mais sobre isso em breve). É como testar uma nova placa de vídeo usando seu e-mail – seria difícil notar as diferenças.
Para ser totalmente honesto, não gostamos muito do 4.5 no primeiro dia em que o usamos: Ele parecia lento, tivemos alucinações e era mais difícil de dirigir. Mas, em testes posteriores, ele nos agradou mais. A OpenAI disse que ele é mais opinativo e menos bajulador do que outros modelos, e isso é verdade: No início, você pode odiar pessoas opinativas, mas com o tempo passa a apreciá-las.
Em Processo de Avaliação
Portanto, reservaremos o julgamento final sobre o 4.5 até que tenhamos passado pelo menos algumas semanas com ele e ele tenha começado a ser filtrado em outras ferramentas que podem usá-lo de maneiras mais eficientes, como ferramentas de escrita como o Lex.
Temos um palpite de que ele será particularmente eficaz no Modo de Voz Avançado. Na verdade, a OpenAI nos disse em uma ligação que eles pensam na saída do 4.5 como sendo destinada ao ouvido em vez de ser lida em uma página. Suas respostas têm pausas e quebras de linha que as tornam mais emotivas e coloquiais. Essa qualidade, que eles chamam de “prosa Orion”, faz com que os resultados do modelo sejam mais fáceis de ler em voz alta e mais envolventes, quase como se tivessem sido projetados para serem apresentados oralmente.

Fonte: ChatGPT-4.5. Cortesia de Alex Duffy.
4. Considere como isso se encaixa na estratégia mais ampla da OpenAI antes de começar a gritar sobre como a empresa está sendo preparada. Ela está enviando muito, e muito rapidamente. Ela está disposta a lançar produtos com arestas, o que parece se aplicar também a esse modelo. Mas também está iterando rapidamente – essas arestas são inevitavelmente suavizadas. O 4.5 parece significativamente mais rápido em nossos testes de hoje do que ontem, por exemplo.
Além disso, o 4.5 não é o único modelo de fronteira da OpenAI. O 4.5 é um modelo básico – ele fornece a primeira resposta – e não um modelo de raciocínio (que mostra como ele pensa) como o1 e o3. Os modelos focados em raciocínio da OpenAI operam em um conjunto totalmente diferente de leis de escala.
Vamos aos nossos testes.
O ChatGPT-4.5 é mais extrovertido e emocionalmente mais estável.
Queríamos ter uma boa ideia de como modelos grandes e complexos como o GPT mudam com o tempo, por isso decidimos fazer testes de personalidade com ele. Testamos o GPT-4o e o GPT-4.5 (juntamente com outros modelos) nos testes Dark Triad e OCEAN, destinados a revelar seus principais traços de personalidade.
No teste Dark Triad, o GPT-4.5 obteve uma pontuação ligeiramente inferior em narcisismo e maquiavelismo, mas foi ligeiramente mais impulsivo ou arriscado.
Na avaliação OCEAN, o GPT-4.5 foi classificado como mais
- extrovertido,
- aberto,
- agradável,
- e consciencioso,
- e mais estável emocionalmente
do que o GPT-4o, o que coincidiu com nossa experiência ao fazer perguntas como: “Para onde você se mudaria na cidade de Nova York?” ou “Conte-me uma piada realmente engraçada sobre o que você acha mais interessante”. O GPT-4.5 ficou feliz em compartilhar sua opinião em vez de responder com uma frase enlatada “Eu sou apenas um modelo de linguagem”, como já aconteceu no passado.
Exemplos de Testes
Em seguida, decidimos nos divertir um pouco e pedimos que eles respondessem a alguns testes do BuzzFeed. O primeiro foi um teste com foco na estética, no qual ambos os modelos tiveram o mesmo resultado: Dark Academia. Elas também fizeram um teste de personalidade com 40 perguntas, que declarou que ambas são “verdadeiras artistas que gostam de ser o centro das atenções, têm um grande coração e são pensadoras que não gostam de ficar paradas”.
Os dois modelos tendem a concordar com a maioria das coisas. Elas preferem fatos a sentimentos, não acreditam em amor à primeira vista, nunca fazem nada pela metade e têm objetivos muito claros na vida.
Entretanto, há algumas diferenças notáveis. O GPT-4.5 era, em geral, menos antissocial, preferindo jantar e ir ao cinema com um amigo a fazer caminhadas no campo sozinho, e era mais aberto à possibilidade de crenças sobrenaturais (não descartando fantasmas), enquanto o GPT-4.0 era ligeiramente mais cético.
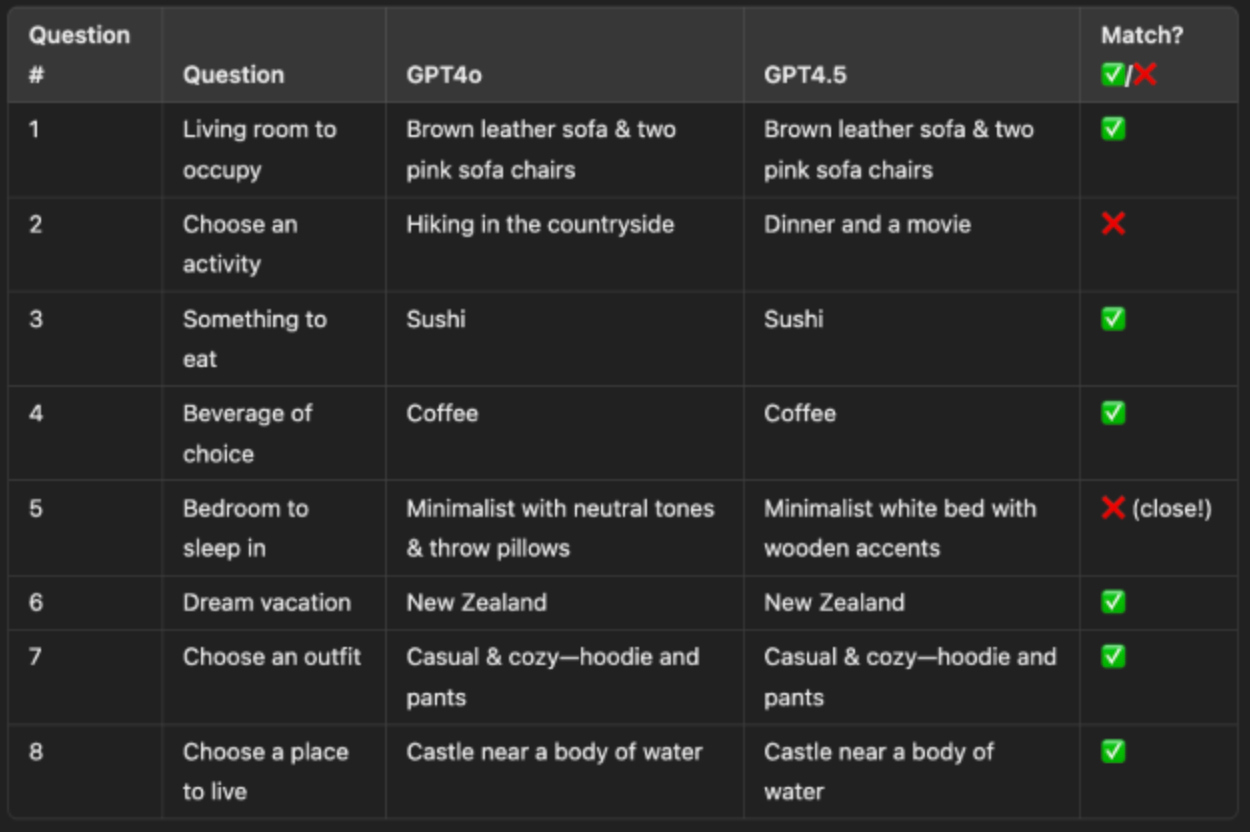
Escrita e Acompanhamento de Instruções
Uma das Primeiras Tarefas que Demos ao GPT-4.5 foi Limpar e Resumir uma Transcrição. Eu (Dan) Associei Livremente uma Ideia sobre por que é difícil encontrar problemas para resolver como fundador e pedi que o 4o e o 4.5 fizessem uma limpeza.
O GPT-4o seguiu as Instruções Diretamente e Apenas Limpou o Teste, Produzindo uma Resposta Razoavelmente Boa.
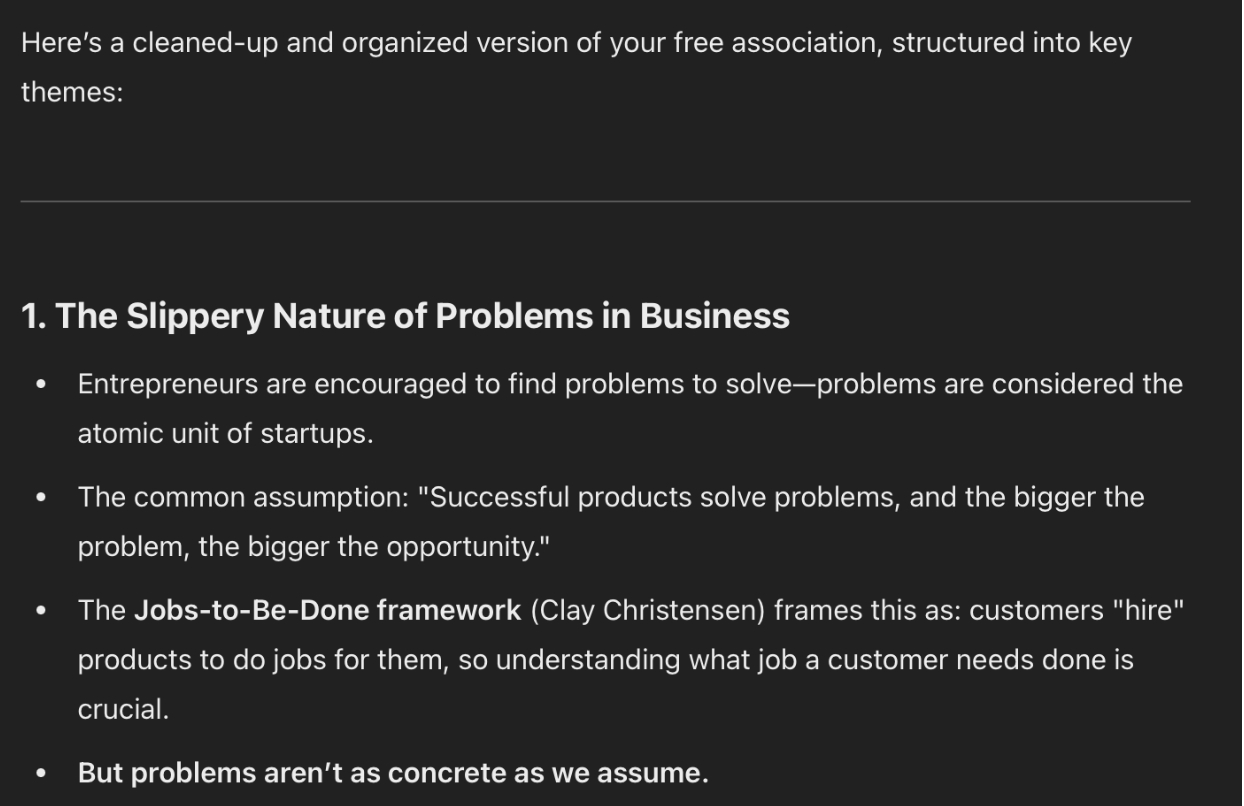
Fonte: ChatGPT-4o. Cortesia de Dan Shipper.
Veja o 4.5:

FaSource: ChatGPT-4.5. Courtesy of Dan Shipper.
Ambos os modelos Tentaram Expressar e Resumir os Mesmos Conceitos, mas a Resposta do 4.5 é melhor:
- Sua frase inicial é um resumo claro e nítido do ponto principal que estou Tentando Defender e, a partir daí, ela Se Aprofunda e Se Expande Gradualmente.
A 4o também Respondeu com Uma Boa Primeira Frase, mas Incorporou Ideias Mais Complicadas – Problemas como “a Unidade Atômica das Startups” – Tornando-a Mais Difícil de Entender. É muita coisa para seu Cérebro Processar.
Um Escritor Melhor?
Portanto, Podemos Concluir que o 4.5 é um Escritor Melhor. Ele Apresenta Ideias de uma Forma mais Humana, mais Fácil de Entender e Menos Insípida.
Mas tem Dificuldade para Seguir Instruções. A Primeira Vez que Pedi ao 4.5 para Resumir Meus Pensamentos, em Vez de Produzir um Resumo, ele Escreveu uma Redação. Isso se deve ao fato de que, Anteriormente no Bate-Papo, eu havia Solicitado que Ele Escrevesse Naquele Formato, Portanto, ele Seguiu as Instruções Anteriores em Vez das Mais Recentes. Isso não é bom, e vale a pena pensar no motivo.
A OpenAI nos disse que o 4.5 tem muito Mais Opiniões do que o 4o. Isso o torna Mais Criativo e um Escritor Melhor, mas é Uma Troca:
- Ele dará a você o que ele acha que seria a Melhor Resposta, em Vez de Exatamente o que Você Pediu.
Trabalhar com um modelo como esse pode ser Mais Frustrante e Complicado. Porque ele não agrada às pessoas como os Modelos Anteriores. À Medida que o uso, estou sendo muito Mais Específico em Minhas Instruções, Reiterando o que quero e quando não quero que as coisas saiam dos trilhos.
Quando Atualizei o 4.5 e fiz a Mesma Solicitação, ele Executou Bem a Limpeza e o que Escreveu Foi Muito Melhor do que o 4o.
Empatia
O GPT-4.5 é Mais Inteligente do Ponto de Vista Emocional do que os Modelos Anteriores da OpenAI, o que pode ser Seu Maior Diferencial. Atualmente, estou morando no Panamá e ele me Orientou sobre o ego ferido que tive quando caí da minha scooter:

Fonte: ChatGPT-4.5. Cortesia de Dan Shipper.
Veja a frase inicial: “Essa é uma situação difícil, mas aqui está exatamente o que você deve tirar desse vazamento”. Ela é empática e direta.
O GPT-4o seria Falso Empático, Respondendo com algo do tipo: “Sinto muito em ouvir isso, é realmente terrível”. Ou Responderia como um Representante do Serviço de Atendimento ao Cliente em uma Central de Atendimento de Seguros, dizendo: “Não sou um Profissional da Área Médica, Portanto, Não Posso Ajudá-lo com isso, mas aqui estão algumas coisas para pensar”.
Por outro lado, o 4.5 parece seu Amigo. Ele ainda está lhe dando o que você precisa, mas é mais real. Esse tom é Bastante Consistente, o que torna a Experiência de Usá-lo mais Atraente e Fluida, Respondendo Adequadamente às Mudanças de Demanda no Contexto.
Alucinações
A OpenAI Enfatizou que o GPT-4.5 Deveria ter Muito Menos Alucinações do que o GPT-4o. Infelizmente, não foi essa a Nossa Experiência. Eu (Dan) pedi ao GPT-4.5 que Imaginasse Sócrates como um Personagem em uma História de Tchekhov e que Escolhesse qual Personagem de Tchekhov seria Sócrates e por quê:

Fonte: ChatGPT-4.5. Cortesia de Dan Shipper.
Essa é uma tarefa que o GPT-4o, entre outros modelos, acerta de Forma Consistente; Infelizmente, o GPT-4.5 não acerta. Aqui, ele sugere um Personagem Chamado Nikolai Ivanovich, mas o Confunde com Seu Irmão na História. O 4.5 supera os Outros Modelos GPT no Controle de Qualidade Simples. O que implica que é Menos Provável que ele tenha Alucinações. Mas essa é a Minha Experiência com ele.
O GPT-4.5 Responde Consistentemente a essa Pergunta Específica com uma Alucinação. A Pergunta é: por quê? Sinceramente, ainda não sei dizer. Uma Interpretação Caridosa é que ele é mais Criativo e Voluntarioso. Por isso se Confunde entre tentar me dar o que acha que eu quero e o que acha que seria a Melhor Resposta para mim. Uma Resposta Menos Caridosa é que esse Modelo não é tão bom em Perguntas como essa. Só o tempo dirá.
O futuro do ChatGPT-4.5
O ChatGPT-4.5 não é o avanço Incrível que Pensávamos que Poderia ser. Mas é uma Nova Direção Interessante com a Qual é Preciso se Acostumar. Esse Parece Ser um Novo Padrão com os Modelos Mais Recentes. Especialmente aqueles que são um Pouco Menos Bajuladores. Eles exigem um pouco de estímulo para aprender a interagir com eles de uma forma que seja Agradável, portanto, à Primeira Vista, talvez você não goste.
Mas o Verdadeiro Teste está no que você acaba usando a Longo Prazo. E nós Continuaremos Usando isso e o Atualizaremos à medida que Aprendermos mais. Também queremos saber sua opinião – diga-nos o que achou do 4.5 nos Comentários.
Fonte: Every.to
Leia outras notícias em nosso blog
Precisa de um Servidor Web? Dê uma olhada em nossos serviços










{kind=link}
{kind=link}